Network Namespaces
The Following Command Will Creates 4 Network Namespaces And Veth Pairs
for i in {1..4}; do
sudo ip netns add ns\$i
sudo ip link add veth\$i type veth peer name pveth\$i
sudo ip link set veth\$i netns ns\$i
sudo ip netns exec ns\$i ip link set dev veth\$i up
sudo ip link set dev pveth\$i up
done
| flag | explanation |
|---|---|
| or i | in {1..4}: iterates over the numbers 1 to 4 |
| -p netns | add ns$i: creates a network namespace for each iteration (1 to 4) |
| -p link | add veth$i type veth peer name pveth$i: creates a veth pair named veth$i and pveth$i |
| -p link | set veth$i netns ns$i: moves the veth$i interface into the network namespace ns$i |
| -p netns | exec ns$i ip link set dev veth$i up: brings the veth$i interface up in the network namespace `ns$i |
| -p link | set dev pveth$i up: brings the pveth$i interface up in the default network namespace |
The Following Command Will Sets Up Ip Forwarding
sysctl -w net.ipv4.ip_forward=1
sysctl -w net.ipv6.conf.all.forwarding=1
| flag | explanation |
|---|---|
| 1 | enables IP forwarding |
| 0 | disables IP forwarding |
The Following Command Will Creates A Virtual Switch Called Br1.
sudo ip link add dev br1 type bridge
| flag | explanation |
|---|---|
| dev br1 | specifies the name of the interface |
| type bridge | specifies the type of the interface |
The Following Command Will Enables The Virtual Switch.
sudo ip link set dev br1 up
| flag | explanation |
|---|---|
| dev br1 | specifies the name of the interface |
The Following Command Will Connects The Pveth1 Interface To The Br1 Virtual switch.
sudo ip link set dev pveth1 master br1
| flag | explanation |
|---|---|
| dev pveth1 | specifies the name of the interface |
| master br1 | specifies the name of the master interface |
Iptables
The Following Command Will Sets Up Masquerade For The 192.168.1.0/24 Network.
iptables -t nat -A POSTROUTING -s 192.168.1.0/24 ! -d 192.168.1.0/24 -j MASQUERADE
| flag | explanation |
|---|---|
| -t nat | specifies the NAT table |
| -A POSTROUTING | appends the rule to the POSTROUTING chain in the NAT table |
| -s 192.168.1.0/24 | matches source addresses in the 192.168.1.0/24 network |
| -d 192.168.1.0/24 | matches destination addresses that are not in the 192.168.1.0/24 network |
| -j MASQUERADE | specifies that matching packets should be masqueraded |
Allows incoming SSH connections to the host
iptables -A INPUT -i br1 -p tcp --dport 22 -j ACCEPT
| flag | explanation |
|---|---|
| -A INPUT | appends the rule to the INPUT chain |
| -i br1 | matches packets arriving at the br1 interface |
| -p tcp | matches TCP packets |
| -dport 22 | matches destination port 22 |
| -j ACCEPT | specifies that matching packets should be accepted |
The Following Command Will Allows Incoming Icmp Requests (Ping) To The Host
iptables -A INPUT -i br1 -p icmp --icmp-type echo-request -j ACCEPT
| flag | explanation |
|---|---|
| -A INPUT | appends the rule to the INPUT chain |
| -i br1 | matches packets arriving at the br1 interface |
| -p icmp | matches ICMP packets |
| -icmp-type | echo-request: matches ICMP echo requests (ping) |
| -j ACCEPT | specifies that matching packets should be accepted |
The Following Command Will Drops All Other Incoming Packets To The Host
iptables -A INPUT -i br1 -j DROP
| flag | explanation |
|---|---|
| -A INPUT | appends the rule to the INPUT chain |
| -i br1 | matches packets arriving at the br1 interface |
| -j DROP | specifies that matching packets should be dropped |
Docker Networking
For Docker containers to communicate with each other and the outside world via the host machine, there has to be a layer of networking involved. Docker supports different types of networks, each fit for certain use cases.
What are different types of Networking in Docker
Docker comes with network drivers geared towards different use cases. Docker’s networking subsystem is pluggable, using drivers.
What is docker0 in terms of Docker Networking
When Docker is installed, a default bridge network named docker0 is created. Each new Docker container is automatically attached to this network, unless a custom network is specified.
Besides docker0, two other networks get created automatically by Docker: host(no isolation between host and containers on this network, to the outside world they are on the same network) and none(attached containers run on container-specific network stack)
Using host network driver for a container, that container’s network stack is not isolated from the Docker host, and use the host’s networking directly.
Host is only available for swarm services on Docker 17.06 and higher.
The host networking driver only works on Linux hosts, and is not supported on Docker for Mac, Docker for Windows, or Docker EE for Windows Server.
The default network driver. If you don’t specify a driver, this is the type of network you are creating. Bridge networks are usually used when your applications run in standalone containers that need to communicate. A bridge network uses a software bridge which allows containers connected to the same bridge network to communicate, while providing isolation from containers which are not connected to that bridge network.
Legacy applications expect to be directly connected to the physical network, rather than routed through the Docker host’s network stack. Macvlan networks assign a MAC address to a container, making it appear as a physical device on your network. The Docker daemon routes traffic to containers by their MAC addresses. We need to designate a physical interface on our Docker host to use for the Macvlan, as well as the subnet and gateway of the Macvlan.
-
None networks
This mode will not configure any IP to the container and doesn’t have any access to the external network as well as to other containers. It does have the loopback address and can be used for running batch jobs.
-
Overlay networks
You have multiple docker host running containers in which each docker host has its own internal private bridge network allowing the containers to communicate with each other however, containers across the host has no way to communicate with each other unless you publish the port on those containers and set up some kind of routing yourself. This is where
Overlay networkcomes into play. With docker swarm you can create an overlay network which will create an internal private network that spans across all the nodes participating in the swarm network as we could attach a container or service to this network using the network option while creating a service. So, the containers across the nodes can communicate over this overlay network.
Introduction to MacVLAN
The macvlan driver is the newest built-in network driver and offers several unique characteristics. It’s a very lightweight driver, because rather than using any Linux bridging or port mapping, it connects container interfaces directly to host interfaces. Containers are addressed with routable IP addresses that are on the subnet of the external network.
As a result of routable IP addresses, containers communicate directly with resources that exist outside a Swarm cluster without the use of NAT and port mapping. This can aid in network visibility and troubleshooting. Additionally, the direct traffic path between containers and the host interface helps reduce latency. macvlan is a local scope network driver which is configured per-host. As a result, there are stricter dependencies between MACVLAN and external networks, which is both a constraint and an advantage that is different from overlay or bridge.
The macvlan driver uses the concept of a parent interface. This interface can be a host interface such as eth0, a sub-interface, or even a bonded host adaptor which bundles Ethernet interfaces into a single logical interface. A gateway address from the external network is required during MACVLAN network configuration, as a MACVLAN network is a L2 segment from the container to the network gateway. Like all Docker networks, MACVLAN networks are segmented from each other – providing access within a network, but not between networks.
The macvlan driver can be configured in different ways to achieve different results. In the below example we create two MACVLAN networks joined to different subinterfaces. This type of configuration can be used to extend multiple L2 VLANs through the host interface directly to containers. The VLAN default gateway exists in the external network.
The db and web containers are connected to different MACVLAN networks in this example. Each container resides on its respective external network with an external IP provided from that network. Using this design an operator can control network policy outside of the host and segment containers at L2. The containers could have also been placed in the same VLAN by configuring them on the same MACVLAN network. This just shows the amount of flexibility offered by each network driver.
Bridge networks
The Bridge network connect two networks while creating a single aggregate network from multiple communication networks or network segments, hence the name bridge.
The bridge driver creates a private network internal to the host so containers on this network can communicate. External access is granted by exposing ports to containers. Docker secures the network by managing rules that block connectivity between different Docker networks.
Behind the scenes, the Docker Engine creates the necessary Linux bridges, internal interfaces, iptables rules, and host routes to make this connectivity possible. In the example highlighted below, a Docker bridge network is created and two containers are attached to it. With no extra configuration the Docker Engine does the necessary wiring, provides service discovery for the containers, and configures security rules to prevent communication to other networks. A built-in IPAM driver provides the container interfaces with private IP addresses from the subnet of the bridge network.
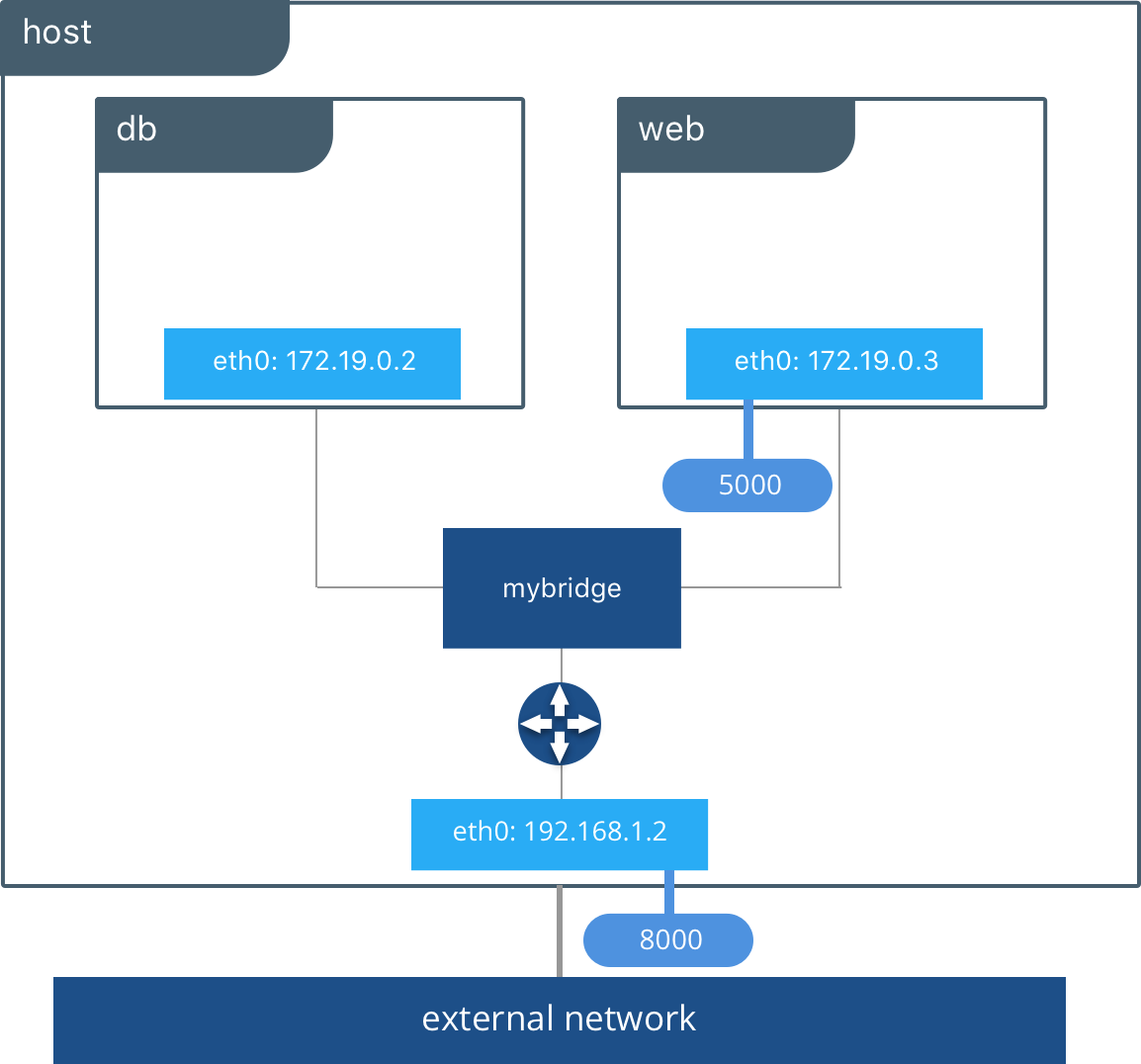
The above application is now being served on our host at port 8000. The Docker bridge is allowing web to communicate with db by its container name. The bridge driver does the service discovery for us automatically because they are on the same network. All of the port mappings, security rules, and pipework between Linux bridges is handled for us by the networking driver as containers are scheduled and rescheduled across a cluster.
The bridge driver is a local scope driver, which means it only provides service discovery, IPAM, and connectivity on a single host. Multi-host service discovery requires an external solution that can map containers to their host location. This is exactly what makes the overlay driver so great.
Overlay networks
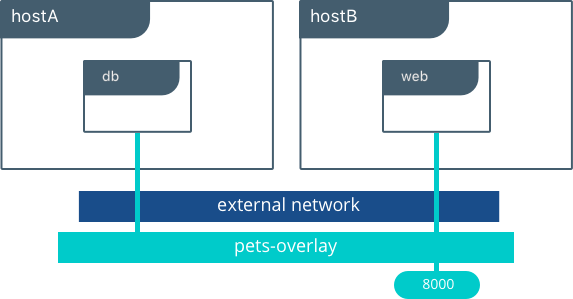
The Overlay Network are usually used to create a virtual network between two separate hosts. Virtual, since the network is build over an existing network.
The built-in Docker overlay network driver radically simplifies many of the complexities in multi-host networking. It is a swarm scope driver, which means that it operates across an entire Swarm or UCP cluster rather than individual hosts. With the overlay driver, multi-host networks are first-class citizens inside Docker without external provisioning or components. IPAM, service discovery, multi-host connectivity, encryption, and load balancing are built right in. For control, the overlay driver uses the encrypted Swarm control plane to manage large scale clusters at low convergence times.
The overlay driver utilizes an industry-standard VXLAN data plane that decouples the container network from the underlying physical network (the underlay). This has the advantage of providing maximum portability across various cloud and on-premises networks. Network policy, visibility, and security is controlled centrally through the Docker Universal Control Plane (UCP).
{kind=link}
In the above example we are still serving our web app on port 8000 but now we have deployed our application across different hosts. If we wanted to scale our web containers, Swarm & UCP networking would load balance the traffic for us automatically.
The overlay driver is a feature-rich driver that handles much of the complexity and integration that organizations struggle with when crafting piecemeal solutions. It provides an out-of-the-box solution for many networking challenges and does so at scale.
The Container Networking Model
The Docker networking architecture is built on a set of interfaces called the Container Networking Model (CNM). The philosophy of CNM is to provide application portability across diverse infrastructures. This model strikes a balance to achieve application portability and also takes advantage of special features and capabilities of the infrastructure.
CNM Constructs
There are several high-level constructs in the CNM. They are all OS and infrastructure agnostic so that applications can have a uniform experience no matter the infrastructure stack.

- Sandbox — A Sandbox contains the configuration of a container’s network stack. This includes management of the container’s interfaces, routing table, and DNS settings. An implementation of a Sandbox could be a Linux Network Namespace, a FreeBSD Jail, or other similar concept. A Sandbox may contain many endpoints from multiple networks.
- Endpoint — An Endpoint joins a Sandbox to a Network. The Endpoint construct exists so the actual connection to the network can be abstracted away from the application. This helps maintain portability so that a service can use different types of network drivers without being concerned with how it’s connected to that network.
- Network — The CNM does not specify a Network in terms of the OSI model. An implementation of a Network could be a Linux bridge, a VLAN, etc. A Network is a collection of endpoints that have connectivity between them. Endpoints that are not connected to a network will not have connectivity on a Network.
Tutorial Application: The Pets App
In the following example, we will use a fictional app called Pets to illustrate the Network Deployment Models. It serves up images of pets on a web page while counting the number of hits to the page in a backend database. It is configurable via two environment variables, DB and ROLE.
DBspecifies the hostname:port or IP:port of thedbcontainer for the web front end to use.ROLEspecifies the “tenant” of the application and whether it serves pictures of dogs or cat.
It consists of web, a Python flask container, and db, a redis container. Its architecture and required network policy is described below.
We will run this application on different network deployment models to show how we can instantiate connectivity and network policy. Each deployment model exhibits different characteristics that may be advantageous to your application and environment.
We will explore the following network deployment models in this section:
- Bridge Driver
- Overlay Driver
- MACVLAN Bridge Mode Driver
Tutorial App: Bridge Driver
This model is the default behavior of the built-in Docker bridge network driver. The bridge driver creates a private network internal to the host and provides an external port mapping on a host interface for external connectivity.
#Create a user-defined bridge network for our application
$ docker network create -d bridge catnet
#Instantiate the backend DB on the catnet network
$ docker run -d --net catnet --name cat-db redis
#Instantiate the web frontend on the catnet network and configure it to connect to a container named `cat-db`
$ docker run -d --net catnet -p 8000:5000 -e 'DB=cat-db' -e 'ROLE=cat' chrch/web
When an IP address is not specified, port mapping will be exposed on all interfaces of a host. In this case the container’s application is exposed on
0.0.0.0:8000. We can specify a specific IP address to advertise on only a single IP interface with the flag-p IP:host_port:container_port. More options to expose ports can be found in the Docker docs.
The web container takes some environment variables to determine which backend it needs to connect to. Above we supply it with cat-db which is the name of our redis service. The Docker Engine’s built-in DNS will resolve a container’s name to its location in any user-defined network. Thus, on a network, a container or service can always be referenced by its name.
With the above commands we have deployed our application on a single host. The Docker bridge network provides connectivity and name resolution amongst the containers on the same bridge while exposing our frontend container externally.
$ docker network inspect catnet
[
{
"Name": "catnet",
"Id": "81e45d3e3bf4f989abe87c42c8db63273f9bf30c1f5a593bae4667d5f0e33145",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": {},
"Config": [
{
"Subnet": "172.19.0.0/16",
"Gateway": "172.19.0.1/16"
}
]
},
"Internal": false,
"Attachable": false,
"Containers": {
"2a23faa18fb33b5d07eb4e0affb5da36449a78eeb196c944a5af3aaffe1ada37": {
"Name": "backstabbing_pike",
"EndpointID": "9039dae3218c47739ae327a30c9d9b219159deb1c0a6274c6d994d37baf2f7e3",
"MacAddress": "02:42:ac:13:00:03",
"IPv4Address": "172.19.0.3/16",
"IPv6Address": ""
},
"dbf7f59187801e1bcd2b0a7d4731ca5f0a95236dbc4b4157af01697f295d4528": {
"Name": "cat-db",
"EndpointID": "7f7c51a0468acd849fd575adeadbcb5310c5987195555620d60ee3ffad37c680",
"MacAddress": "02:42:ac:13:00:02",
"IPv4Address": "172.19.0.2/16",
"IPv6Address": ""
}
},
"Options": {},
"Labels": {}
}
]
In this output, we can see that our two containers have automatically been given ip addresses from the 172.19.0.0/16 subnet. This is the subnet of the local catnet bridge, and it will provide all connected containers a subnet from this range unless they are statically configured.
Tutorial App: Multi-Host Bridge Driver Deployment
Deploying a multi-host application requires some additional configuration so that distributed components can connect with each other. In the following example we explicitly tell the web container the location of redis with the environment variable DB=hostB:8001. Another change is that we are port mapping port 6379 inside theredis container to port 8001 on the hostB. Without the port mapping, redis would only be accessible on its connected networks (the default bridge in this case).
host-A $ docker run -d -p 8000:5000 -e 'DB=host-B:8001' -e 'ROLE=cat' --name cat-web chrch/web
host-B $ docker run -d -p 8001:6379 redis
In this example we don’t specify a network to use, so the default Docker
bridgenetwork will exist on every host.
When we configure the location of redis at host-B:8001, we are creating a form of service discovery. We are configuring one service to be able to discover another service. In the single host example, this was done automatically because Docker Engine provided built-in DNS resolution for the container names. In this multi-host example we are doing this manually.
cat-webmakes a request to theredisservice athost-B:8001- On
host-Athehost-Bhostname is resolved tohost-B’s IP address by the infrastructure’s DNS - The request from
cat-webis masqueraded to use thehost-AIP address. - Traffic is routed or bridged by the external network to
host-Bwhere port8001is exposed. - Traffic to port
8001is NATed and routed onhost-Bto port6379on thecat-dbcontainer.
The hardcoding of application location is not typically recommended. Service discovery tools exist that provide these mappings dynamically as containers are created and destroyed in a cluster. The overlay driver provides global service discovery across a cluster. External tools such as Consul and etcd also provide service discovery as an external service.
In the overlay driver example we will see that multi-host service discovery is provided out of the box, which is a major advantage of the overlay deployment model.
Bridge Driver Benefits and Use-Cases
- Very simple architecture promotes easy understanding and troubleshooting
- Widely deployed in current production environments
- Simple to deploy in any environment from developer laptops to production data center
Tutorial App: Overlay Driver
This model utilizes the built-in overlay driver to provide multi-host connectivity out of the box. The default settings of the overlay driver will provide external connectivity to the outside world as well as internal connectivity and service discovery within a container application. The Overlay Driver Architecture section reviews the internals of the Overlay driver which you should review before reading this section.
In this example we are re-using the previous Pets application. Prior to this example we already set up a Docker Swarm. For instructions on how to set up a Swarm read the Docker docs. When the Swarm is set up, we can use the docker service create command to create containers and networks that will be managed by the Swarm.
The following shows how to inspect your Swarm, create an overlay network, and then provision some services on that overlay network. All of these commands are run on a UCP/swarm controller node.
#Display the nodes participating in this swarm cluster
$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
a8dwuh6gy5898z3yeuvxaetjo host-B Ready Active
elgt0bfuikjrntv3c33hr0752 * host-A Ready Active Leader
#Create the dognet overlay network
$ docker network create -d overlay --subnet 10.1.0.0/24 --gateway 10.1.0.1 dognet
#Create the backend service and place it on the dognet network
$ docker service create --network dognet --name dog-db redis
#Create the frontend service and expose it on port 8000 externally
$ docker service create --network dognet -p 8000:5000 -e 'DB=dog-db' -e 'ROLE=dog' --name dog-web chrch/web
We pass in DB=dog-db as an environment variable to the web container. The overlay driver will resolve the service name dog-db and load balance it to containers in that service. It is not required to expose the redis container on an external port because the overlay network will resolve and provide connectivity within the network.
Inside overlay and bridge networks, all TCP and UDP ports to containers are open and accessible to all other containers attached to the overlay network.
The dog-web service is exposed on port 8000, but in this case the routing mesh will expose port 8000 on every host in the Swarm. We can test to see if the application is working by going to <host-A>:8000 or <host-B>:8000 in the browser.
Complex network policies can easily be achieved with overlay networks. In the following configuration, we add the cat tenant to our existing application. This will represent two applications using the same cluster but requirE network micro-segmentation. We add a second overlay network with a second pair of web and redis containers. We also add an admin container that needs to have access to both tenants.
To accomplish this policy we create a second overlay network, catnet, and attach the new containers to it. We also create the admin service and attach it to both networks.
$ docker network create -d overlay --subnet 10.2.0.0/24 --gateway 10.2.0.1 catnet
$ docker service create --network catnet --name cat-db redis
$ docker service create --network catnet -p 9000:5000 -e 'DB=cat-db' -e 'ROLE=cat' --name cat-web chrch/web
$ docker service create --network dognet --network catnet -p 7000:5000 -e 'DB1=dog-db' -e 'DB2=cat-db' --name admin chrch/admin
This example uses the following logical topology:
dog-webanddog-dbcan communicate with each other, but not with thecatservice.cat-webandcat-dbcan communicate with each other, but not with thedogservice.adminis connected to both networks and has reachability to all containers.
Overlay Benefits and Use Cases
- Very simple multi-host connectivity for small and large deployments
- Provides service discovery and load balancing with no extra configuration or components
- Useful for east-west micro-segmentation via encrypted overlays
- Routing mesh can be used to advertise a service across an entire cluster
Tutorial App: MACVLAN Bridge Mode
There may be cases where the application or network environment requires containers to have routable IP addresses that are a part of the underlay subnets. The MACVLAN driver provides an implementation that makes this possible. As described in the MACVLAN Architecture section, a MACVLAN network binds itself to a host interface. This can be a physical interface, a logical sub-interface, or a bonded logical interface. It acts as a virtual switch and provides communication between containers on the same MACVLAN network. Each container receives a unique MAC address and an IP address of the physical network that the node is attached to.
In this example, the Pets application is deployed on to host-A and host-B.
#Creation of local macvlan network on both hosts
host-A $ docker network create -d macvlan --subnet 192.168.0.0/24 --gateway 192.168.0.1 -o parent=eth0 macvlan
host-B $ docker network create -d macvlan --subnet 192.168.0.0/24 --gateway 192.168.0.1 -o parent=eth0 macvlan
#Creation of web container on host-A
host-A $ docker run -it --net macvlan --ip 192.168.0.4 -e 'DB=dog-db' -e 'ROLE=dog' --name dog-web chrch/web
#Creation of db container on host-B
host-B $ docker run -it --net macvlan --ip 192.168.0.5 --name dog-db redis
When dog-web communicates with dog-db, the physical network will route or switch the packet using the source and destination addresses of the containers. This can simplify network visibility as the packet headers can be linked directly to specific containers. At the same time application portability is decreased as container IPAM is tied to the physical network. Container addressing must adhere to the physical location of container placement in addition to preventing overlapping address assignment. Because of this, care must be taken to manage IPAM externally to a MACVLAN network. Overlapping IP addressing or incorrect subnets can lead to loss of container connectivity.
MACVLAN Benefits and Use Cases
- Very low latency applications can benefit from the
macvlandriver because it does not utilize NAT. - MACVLAN can provide an IP per container, which may be a requirement in some environments.
- More careful consideration for IPAM must be taken in to account.